entos不支持中文怎么解决
1,示例
图中名为一个.sql文件的一段内容,是一个数据库文件。其在windows中打开显示正常,在Linux中,中文部分显示为乱码。

注意:这个与数据库乱码的情况不同,属于文件内容的乱码。
2,分析
Linux系统与windows系统在编码上有显著的差别。Windows中的文件的格式默认是GBK(gb2312),而Linux系统中文件的格式默认是UTF-8。这两个系统就好比是中国和日本。文件就好比是一个人,如果要在另外的国家居住就要办理居住许可证,使用他国的证件(编码和字符集),否则是不被允许的黑户。因此,解决中文乱码问题要从编码和字符集着手。
文件出现编码错误的原因:
当前系统的字符集有问题
某个文件的编码有问题
3,解决方案
3.1方案一:从系统的字符集处理
当系统中多个文件的内容出现乱码问题,或者中文文件名显示乱码时,就先从系统的字符集处理。
常用字符集:
中文LANG=“zh_CN.UTF-8”
英文LANG=“en_US.UTF-8”
或LANG=C
1,查看字符集
<1>查看当前系统默认采用的字符集locale
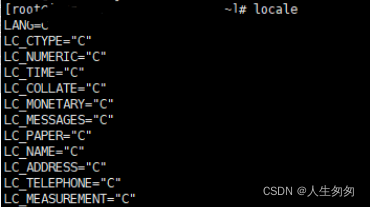
<2>查看系统当前字符集echo $LANG
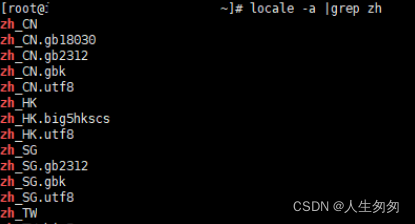
<3>查看系统是否安装中文字符集
出现zh开头的,即为安装了中文字符集
如未安装,需执行: yum install kde-l10n-Chinese
#yum reinstall glibc-commonlocale -a |grep zh
2,修改系统字符集
<1>修改系统字符集为中文
如果前面查看到的系统当前的字符集是英文,通常修改系统字符集为中文即可成功。source /etc/profile
临时修改(当前终端生效):
export LANG=”zh_CN.UTF-8″
永久修改:
echo “export LANG=zh_CN.UTF-8” >> /etc/profile
source /etc/profile
<2>查看
- echo $LANG
3.2 解决方法二:从文件的编码处理
当系统的字符集为中文,文件的中文部分仍然显示乱码,就从文件的编码格式处理。
1,查看文件编码
<1>查看文件编码(vim方式)
用vim打开文件,输入:set fileencoding


fileencoding后即为该文件编码格式
<2>查看文件编码(file方式)file 文件名 或 file --mime-encoding 文件名
- 1
- 2
- 3

2,修改文件的字符集
<1>文件的编码转换(vim方式)
这个方法,仅在vim查看时进行编码转换,文件实际上本身编码并未转换,仅仅只是可看到。临时转换: 用vim打开文件,输入:set fileencoding=utf-8 永久转换(先确认vimrc位置): echo "set encoding=utf-8 fileencodings=ucs-bom,utf-8,cp936" >> /etc/vimrc 或 echo "set encoding=utf-8 fileencodings=ucs-bom,utf-8,cp936" >> ~/.vimrc vim会依照fileencodings提供的编码列表,查找合适的编码,如果没有找到就用latin-1(ASCII)编码打开.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
<2>文件的编码转换(iconv方式)
该命令可进行文件内容的编码转换,并输出到其他位置(文件)命令参数 -f encoding 把字符由原来的编码开始转换 -t encoding 把字符转换为新编码 -l 列出支持的编码字符(可选) -o file 指定输出文件(可选) -c 忽略输出的非法字符(可选) -s 禁止输出警告信息(可选) --verbose 显示进度(可选)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
{1}.列出当前支持的字符编码iconv -l
- 1
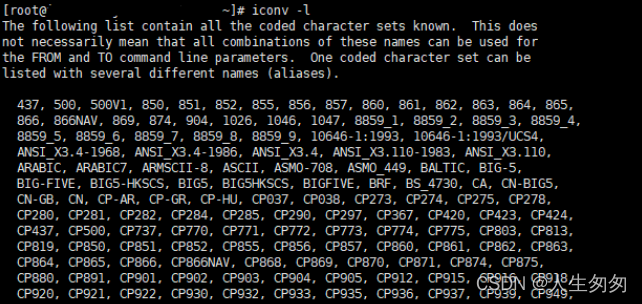
{2}.编码转换基本格式: iconv -f 原编码 -t 新编码 原文件 -o 新文件 或 iconv -f 原编码 -t 新编码 原文件 > 新文件 示例:将UTF-8编码的wx.txt文件转换为GB2312编码的test01.txt iconv -f UTF-8 -t GB2312 wx.txt -o test01.txt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
<3>文件名编码转换(convmv方式)
该命令可转换文件名的编码(只是文件名编码的转换,文件内容不会发生变化)
安装命令:yum -y install convmv命令参数 -f 后面是原来的编码方式 -t 后面是要转换为的编码方式 -r 递归处理子文件夹 -i 询问每一个转换 --notest 真实的执行,在默认情况下只会测试(只能以root权限执行)
- 1
- 2
- 3
- 4
- 5
- 6
{1}编码转换基本格式: convmv -f 原编码 -t 新编码 --notest(可选) 文件名 或 convmv -f 原编码 -t 新编码 --notest(可选) -r 目录名 示例:将read目录下的UTF-8编码的文件名转换为GBK编码 convmv -f UTF-8 -t GBK --notest -r read/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
<4>文件的编码转换(enca方式)
该工具能自动识别文件编码,且支持批量转换
安装命令:yum -y install enca
{1}.编码转换基本格式 enca -L 原编码 -x 新编码 文件名 或 enca -L 原编码 -x 新编码 目录名 示例1:把当前目录下的所有文件都转成utf-8 enca -L zh_CN -x utf-8 * 示例2:检查文件的编码 enca -L zh_CN test.txt 示例3:将test.txt文件编码转换为"UTF-8"编码 enca -L zh_CN -x UTF-8 test.txt 示例4:将test.txt文件编码转换为"UTF-8"编码,并输入test2.txt中 enca -L zh_CN -x UTF-8 < test.txt > test2.txt